Finding an Efficient Solution on Reading and Comparing CSV files
I have always worked with Linux Systems and thus Bash was my go to tool for some specific tasks. But now I am much more aware with Python than Bash as it does give me better grasp on things. I am not saying that for server scripting, Bash can not do some tasks. It can be used in a vast area of things to solve. But I am now comfortable with Python more.
Recently, I did stumble upon of a task that was related to comparing two huge CSV files.
- file1.csv
- file2.csv
file2.csv is larer than file1. It is not at all sorted. But there are some common in both of them but not all. What was needed to do-
- Make a file from file1 at which no items of file1 exists in file2.
- Make a file from file2 at which no items of file2 exists in file1.
So, I need to make file1.csv unique from file2 and vice versa.
As an example of the items in the files,
id,username
2342,fahad
4456,ronald
705,tonySo, I wanted to open the files in python.
import csv
with open("file1.csv", newline='') as csvfile:
creader = list(csv.reader(csvfile, delimiter=','))
Above code will just read the csv file in memory and make a list of list.
[['\ufeffid', 'username'], ['2342', 'fahad']]I thought to open the both file and take it to a list of list and do list comprehension and check how it is doing. It was taking too much time. I guessed to calculate the time and check for better solution.
For time calculation-
import logging
import time
def TimeCalculator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start = time.perf_counter() # Alternatively, you can use time.process_time()
func_return_val = func(*args, **kwargs)
end = time.perf_counter()
timeit_message = 'Time Took: {0:<10}.{1:<8} : {2:<8} Seconds'.format(func.__module__, func.__name__, end - start)
logging.warning(timeit_message)
return func_return_val
return wrapper
I have used this decorator to calculate execution time of function calls. To calculate execution time of python file, I will use time() command of bash.
Approach 1
import csv
import functools
import time
import logging
def TimeCalculator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start = time.perf_counter() # Alternatively, you can use time.process_time()
func_return_val = func(*args, **kwargs)
end = time.perf_counter()
timeit_message = 'Time Took: {0:<10}.{1:<8} : {2:<8} Seconds'.format(func.__module__, func.__name__, end - start)
logging.warning(timeit_message)
return func_return_val
return wrapper
if __name__ == "__main__":
files = ["file1.csv", "file2.csv"]
new_files = ["unique_"+x for x in files]
file1list = []
file2list = []
for _ in files:
with open(_, newline='') as csvfile:
creader = list(csv.reader(csvfile, delimiter=','))
if "file1" in _:
file1list = creader
else:
file2list = creader
@TimeCalculator
def make_unique_file1():
result = [x for x in file1list if x not in file2list]
with open(new_files[0], "w") as f:
writer = csv.writer(f)
writer.writerows(result)
return result
@TimeCalculator
def make_unique_file2():
result = [x for x in file2list if x not in file1list]
with open(new_files[1], "w") as f:
writer = csv.writer(f)
writer.writerows(result)
return result
unique_f1 = make_unique_file1()
unique_f2 = make_unique_file2()
result = {
"file1": {
"actual_size": len(file1list),
"unique_size": len(unique_f1)
},
"file2": {
"actual_size": len(file2list),
"unique_size": len(unique_f2)
}
}
print(result)
To run the test:
$ time(python3 approach1.py)
Result:
WARNING:root:Time Took: __main__ .make_unique_file1 : 284.615873416 Seconds
WARNING:root:Time Took: __main__ .make_unique_file2 : 242.03096016700005 Seconds
{'file1': {'actual_size': 91430, 'unique_size': 84026}, 'file2': {'actual_size': 148803, 'unique_size': 141399}}
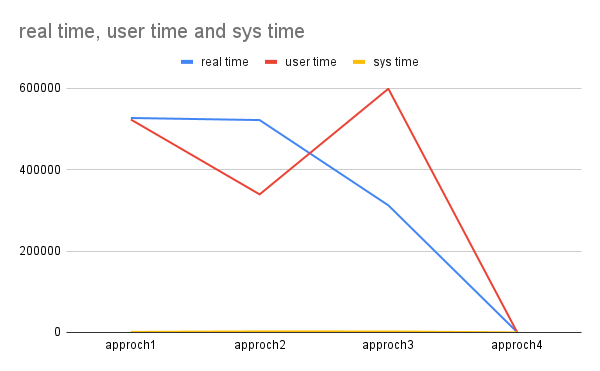
real 8m46.991s
user 8m43.204s
sys 0m1.393s
Now, I thought to use threading to make it a little bit faster.
Approach 2
import csv
import functools
import time
import logging
import threading
def TimeCalculator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start = time.perf_counter() # Alternatively, you can use time.process_time()
func_return_val = func(*args, **kwargs)
end = time.perf_counter()
timeit_message = 'Time Took: {0:<10}.{1:<8} : {2:<8} Seconds'.format(func.__module__, func.__name__, end - start)
logging.warning(timeit_message)
return func_return_val
return wrapper
if __name__ == "__main__":
files = ["file1.csv", "file2.csv"]
new_files = ["unique_"+x for x in files]
file1list = []
file2list = []
for _ in files:
with open(_, newline='') as csvfile:
creader = list(csv.reader(csvfile, delimiter=','))
if "file1" in _:
file1list = creader
else:
file2list = creader
@TimeCalculator
def make_unique_file1():
result = [x for x in file1list if x not in file2list]
with open(new_files[0], "w") as f:
writer = csv.writer(f)
writer.writerows(result)
to_return = {
"file1": {
"actual_size": len(file1list),
"unique_size": len(result)
}
}
return to_return
@TimeCalculator
def make_unique_file2():
result = [x for x in file2list if x not in file1list]
with open(new_files[1], "w") as f:
writer = csv.writer(f)
writer.writerows(result)
to_return = {
"file2": {
"actual_size": len(file2list),
"unique_size": len(result)
}
}
return to_return
t1 = threading.Thread(target=make_unique_file1)
t1.start()
t2 = threading.Thread(target=make_unique_file2)
t2.start()
I have imported the threading function. Also did some change in return or print the result for not wanting to use the thread join.
$ time(python3 approach2.py)
Result:
WARNING:root:Time Took: __main__ .make_unique_file2 : 478.923104584 Seconds WARNING:root:Time Took: __main__ .make_unique_file1 : 521.570241958 Seconds real 8m41.897s user 8m39.290s sys 0m2.620s
Not at all useful. But file2 took less time and finished earlier than file1.
Approach 3
import csv
import functools
import time
import logging
import multiprocessing
def TimeCalculator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start = time.perf_counter() # Alternatively, you can use time.process_time()
func_return_val = func(*args, **kwargs)
end = time.perf_counter()
timeit_message = 'Time Took: {0:<10}.{1:<8} : {2:<8} Seconds'.format(func.__module__, func.__name__, end - start)
logging.warning(timeit_message)
return func_return_val
return wrapper
@TimeCalculator
def make_unique_file1(new_files, file1list, file2list):
result = [x for x in file1list if x not in file2list]
with open(new_files[0], "w") as f:
writer = csv.writer(f)
writer.writerows(result)
to_return = {
"file1": {
"actual_size": len(file1list),
"unique_size": len(result)
}
}
return to_return
@TimeCalculator
def make_unique_file2(new_files, file1list, file2list):
result = [x for x in file2list if x not in file1list]
with open(new_files[1], "w") as f:
writer = csv.writer(f)
writer.writerows(result)
to_return = {
"file2": {
"actual_size": len(file2list),
"unique_size": len(result)
}
}
return to_return
if __name__ == "__main__":
files = ["file1.csv", "file2.csv"]
new_files = ["unique_"+x for x in files]
file1list = []
file2list = []
for _ in files:
with open(_, newline='') as csvfile:
creader = list(csv.reader(csvfile, delimiter=','))
if "file1" in _:
file1list = creader
else:
file2list = creader
# creating processes
p1 = multiprocessing.Process(target=make_unique_file1, kwargs={
"new_files": new_files, "file1list": file1list, "file2list": file2list
})
p1.start()
p2 = multiprocessing.Process(target=make_unique_file2, kwargs={
"new_files": new_files, "file1list": file1list, "file2list": file2list
})
p2.start()
Result:
WARNING:root:Time Took: __mp_main__.make_unique_file1 : 296.335635875 Seconds WARNING:root:Time Took: __mp_main__.make_unique_file2 : 311.145113083 Seconds real 5m12.346s user 9m58.897s sys 0m2.419s
I have used multiprocess. It is similar of threading on execution. Though it has other ways to implement.
What I came to understand is, I am doing odd things with the list comprehension. I can use other ways to minimize the for..loop time complexity.
Approach 4
import csv
import functools
import time
import logging
import multiprocessing
def TimeCalculator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start = time.perf_counter() # Alternatively, you can use time.process_time()
func_return_val = func(*args, **kwargs)
end = time.perf_counter()
timeit_message = 'Time Took: {0:<10}.{1:<8} : {2:<8} Seconds'.format(func.__module__, func.__name__, end - start)
logging.warning(timeit_message)
return func_return_val
return wrapper
@TimeCalculator
def make_unique_file1(new_files, file1list, file2list):
sfile1list = set(file1list)
sfile2list = set(file2list)
result = sfile1list - sfile2list
with open(new_files[0], "w") as f:
writer = csv.writer(f)
writer.writerows(result)
to_return = {
"file1": {
"actual_size": len(file1list),
"unique_size": len(result)
}
}
return to_return
@TimeCalculator
def make_unique_file2(new_files, file1list, file2list):
sfile1list = set(file1list)
sfile2list = set(file2list)
result = sfile2list - sfile1list
with open(new_files[1], "w") as f:
writer = csv.writer(f)
writer.writerows(result)
to_return = {
"file2": {
"actual_size": len(file2list),
"unique_size": len(result)
}
}
return to_return
if __name__ == "__main__":
files = ["file1.csv", "file2.csv"]
new_files = ["unique_"+x for x in files]
file1list = []
file2list = []
for _ in files:
with open(_, newline='') as csvfile:
creader = list(csv.reader(csvfile, delimiter=','))
if "file1" in _:
file1list = [tuple(x) for x in creader]
else:
file2list = [tuple(x) for x in creader]
# creating processes
p1 = multiprocessing.Process(target=make_unique_file1, kwargs={
"new_files": new_files, "file1list": file1list, "file2list": file2list
})
p1.start()
p2 = multiprocessing.Process(target=make_unique_file2, kwargs={
"new_files": new_files, "file1list": file1list, "file2list": file2list
})
p2.start()
Result:
WARNING:root:Time Took: __mp_main__.make_unique_file1 : 0.11172 Seconds WARNING:root:Time Took: __mp_main__.make_unique_file2 : 0.194361834 Seconds real 0m0.949s user 0m0.784s sys 0m0.143s
That is significantly faster than the others.
There are caveats too. The size of the CSV file is still not that huge, thus I could open the file and took all the items into memory. But if the size is larger, problem can arise. I will try some other better ways thinking about size.
Also, I will soon share further ways with these approaches.